Came across this talk by Maciej Ceglowski on Big Data and comparing it to the Nuclear Power Plant industry. I think it’s a great talk clearly highlighting the issues around big data in a way that makes it understandable.
What do you think?
Came across this talk by Maciej Ceglowski on Big Data and comparing it to the Nuclear Power Plant industry. I think it’s a great talk clearly highlighting the issues around big data in a way that makes it understandable.
What do you think?
On the DataMeet list we have started referring to each other as DMers. So I wanted to start highlighting people who are pretty interesting and have a great insights into open data.
Dilip has been a major contributor to the list for a few years. He is always sharing data, advise, and information. He has contributed to the pincode and shapefile conversations and it always a source of support.
Where are you from? What do you do?
I am from India, born and studied in Goa. Presently (last 28 years) based in Delhi.
By qualification I am a Mechanical Engineer.
Presently I am a freelancer (worked as an employee between 1981 and 1992) As a one man SOHO professional I provide services to different Private organisations for themselves and some Private organisations in turn providing services to Government agencies. Area of specialisation is mainly application of computers to Engineering, CAD, Technical publications, Cartography, Data Maintenance, MIS reports and custom software.
I am a part time hobby programmer and have been programming since 1983 for fun and to automate my own work– VB, VBA and Autolisp.
How did you find out about DataMeet?
I wanted to make and publish editable version of Election maps and was looking for the source of updated maps after delimitation. I bumped in to [Raphael] Susewind’s Blog and via that page came to know about Datameet.
Why are you interested in data?
Mainly to make editable maps in common software, which I have a plan to offer free. More recently I have been doing less work on CAD and more on databases. In the process I am also hooked to the beauty of clean data represented especially in Database as against Excel.
Do you believe in open data? and why?
Yes, At least the data that is relevant to society as a whole.
Reasons:
What do you hope to learn?
I hope to interact with varied people and know newer things and techniques that I might not have even heard of before.
What is your impression of the DataMeet community?
Good people but It is too small, needs to be bigger.
What kind of civic projects do you work on? What kinds of civic projects are you interested in working on?
I have worked on Water Supply and Sewer networks mainly the application of computers for several years. A little on Storm water.
In future I wold love to work on Transportation modeling.
Share a visualization that you saw recently that made a big impression? Share an article you have read recently that made a big impression? (does not have to be data related)
Share a visualization that you saw recently that made a big impression? Share an article you have read recently that made a big impression? (does not have to be data related)
A visualisation about Evolution.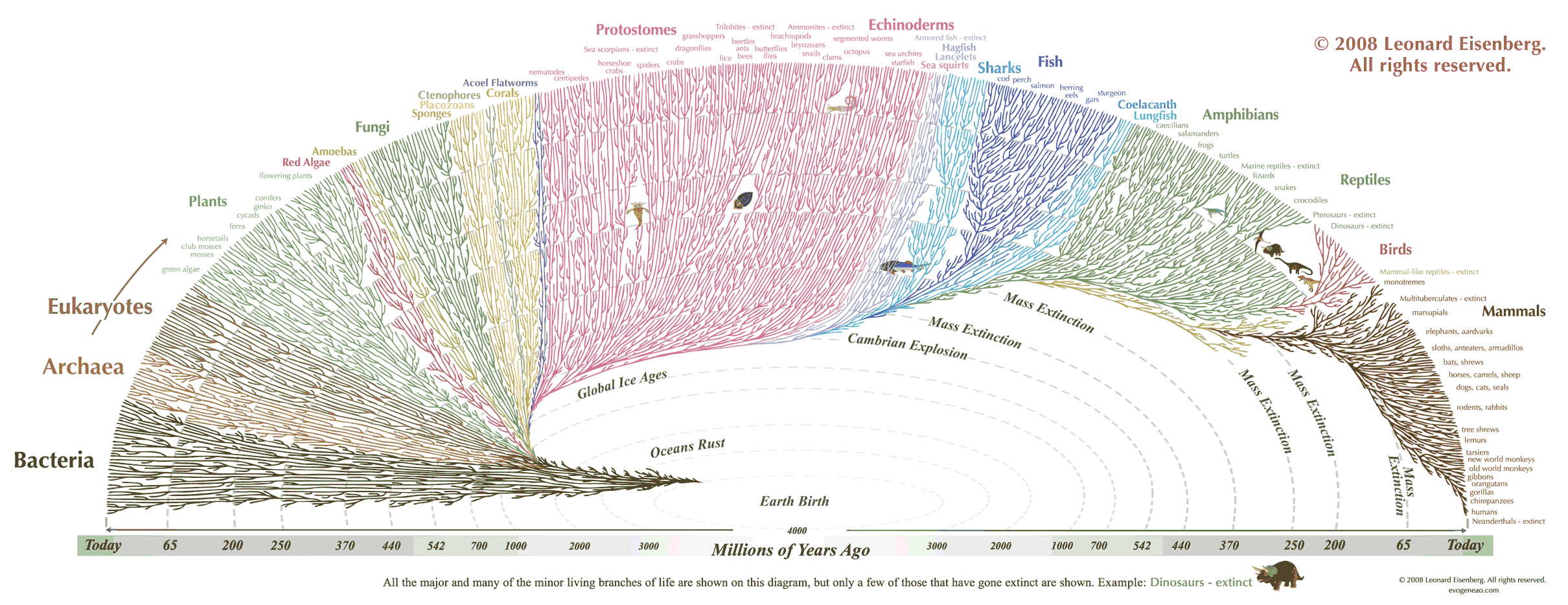
Late post
Open A ccess Week is used as an opportunity to spread awareness of open access issues throughout the world. It was Oct 24th to the 30th last year. Shravan and Mahroof from the Ahmedabad Chapter suggested we do the first every multi city hangout and bring together different groups working on openness issues throughout the country.
ccess Week is used as an opportunity to spread awareness of open access issues throughout the world. It was Oct 24th to the 30th last year. Shravan and Mahroof from the Ahmedabad Chapter suggested we do the first every multi city hangout and bring together different groups working on openness issues throughout the country.
For the event we had a Google Hangout with:
Data.Gov.In started us off with Alka Misra and Sitansu participating from Delhi. They spoke about new features on Data.Gov.in, new datasets and visualizations available. They were also there to extend invites for more participation from the community.
Rahmanuddin from Access to Knowledge then spoke about Wikipedia and their community dedicated to local language knowledge sharing. They also had pertinent questions to Data.Gov.In regarding using open licenses. Since Wikipedia can’t use any data from Data.Gov.In since a license isn’t specified.
Ahmedabad Chapter went next. Ramya Bhatt, Assistant Municipal Commissioner from Ahmedabad, came and gave a brief talk about their plans for open data and smart cities. Alka from Data.Gov.In offered assistance. Then some students from Dhirubhai Ambani Institute of Information and Technology’s machine learning program used some data from Data.Gov.in to do analysis at the event. They looked at high budget allocation per state and drop out rates.
Open Access India’s Sridhar Gutam briefly went through the plans OAI has for the upcoming year to promote open access science and journals.
Hyderabad DataMeet is a new and yet to really take shape meet up but we were happy to see a first attempt. Sailendra took the lead as the organizer and brought together some people from IIM Hyderabad. Srinivas Kodali was there to talk about all the data he had made available that week.
 Banalore DataMeet was there to share what has been going on with DataMeet and any new iniatives in Open Access
Banalore DataMeet was there to share what has been going on with DataMeet and any new iniatives in Open Access
It was a great event, and as with all online events there were some technical difficulties but everyone was patient. It was awesome to see how the open culture space has grown, and to see so many new DataMeet chapters.
You can see the event below:
I hope we do one again soon minus the technical difficulties.
There is no greater success story for open data than GPS. The decision by the US government to make it available so it can be used for commercial purposes is the stuff of lore and what propels so much of the enthusiasm for open data.
Audiomatic’s show The Intersection is a podcast hosted by the dynamic duo Padmaparna Ghosh and Samanth Subramanian who explore interesting topics every other week.
Last week they did a show about GPS and it’s history and uses. Our own Thejesh GN was interviewed about his hobby of using GPS to go on treasure hunts. They also talk about the Indian Government’s move to create a national GPS infrastructure with their own satellite so they don’t have to rely on the US.
I found the podcast informative and interesting and it hit on an important note as to why open data in India is so important.
Like GPS infrastructure to support India’s defense; data in India also needs to be invested in and promoted so that the reliance on others can reduce. Why is Google Maps, not Survey of India, the source of mapping information in India? Why are their so many private data collection networks set up with foreign funds and private interests?Because GOI doesn’t invest in the potential of their data to build markets and make their job easier and more effective.
Open data is just one way of showcasing how better data can be used as well as offer guidance on how the government can invest in data collection and dissemination.
Anway it is a great podcast please give it a listen.
Open Bangalore has been a pioneer in opening up several data sets that help understand Bangalore city. This includes the network of Bangalore Metropolitan Transport Corporation (BMTC). The BMTC operates over 2000 routes in the city and region of Bangalore and is the only real mode of public transit system in the city. Some of us at DataMeet took to time understand its network better by performing some basic analysis on the gathered dataset. The data set had bus stops, routes and trips. We inspected frequency, coverage, redundancy and reachability.
BMTC is known for its many long routes. Route 600 is the longest, making a roundtrip around the city, covering 117 km in about 5 hours. There are 5 trips a day, and these buses are packed throughout. It should be noted that while the route traces the edges of the city in the west and north, it encircles the larger industrial clusters of the east and south.
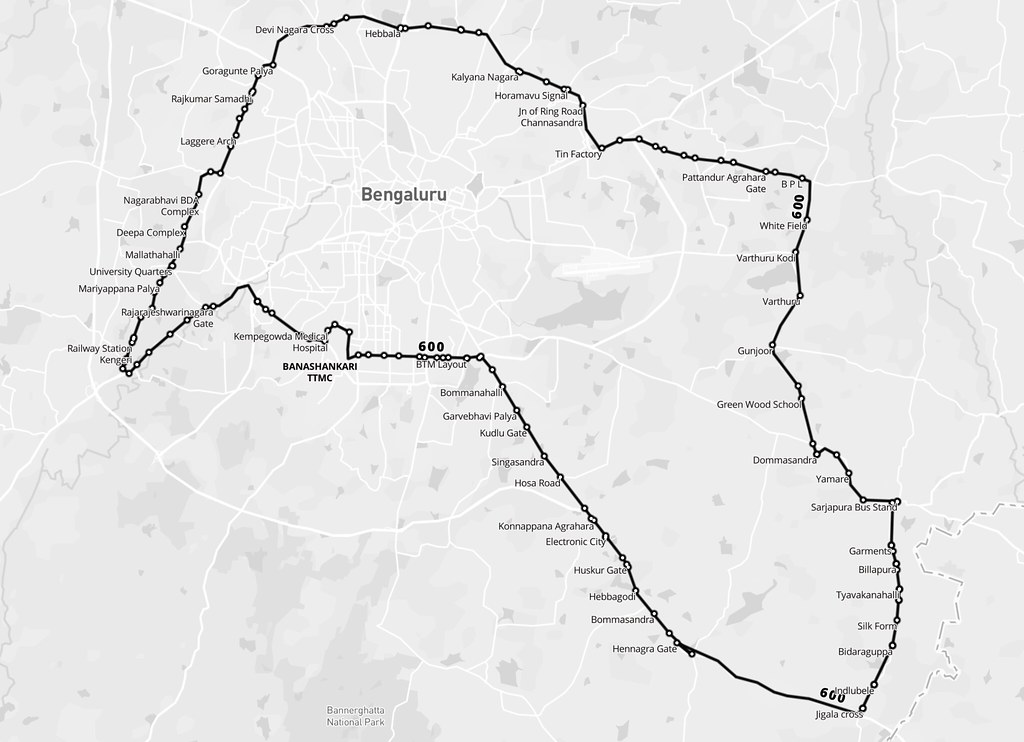
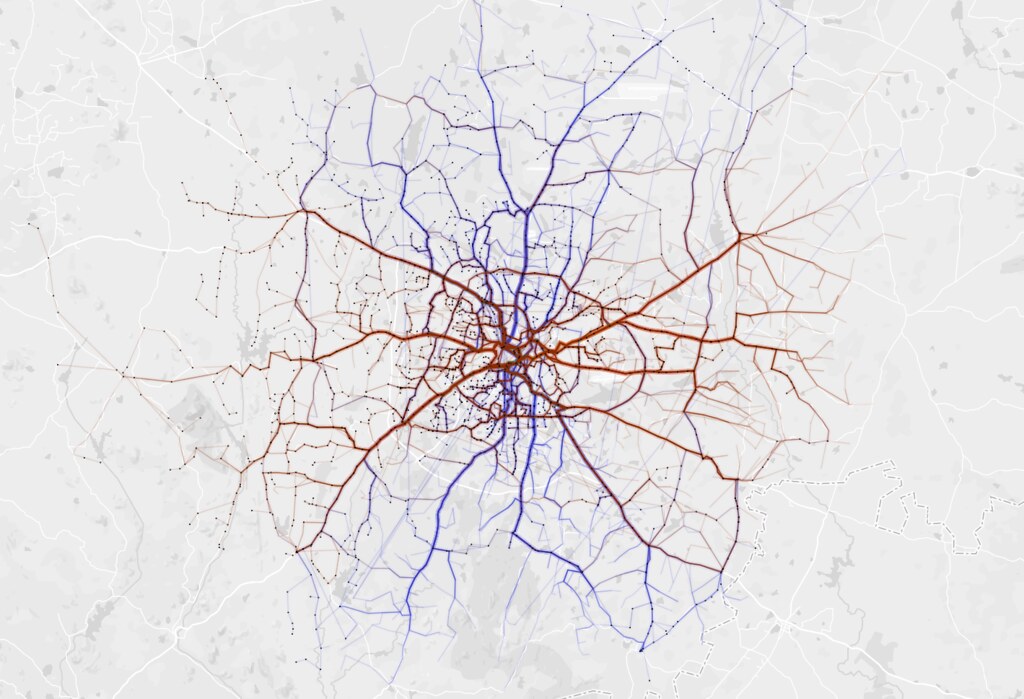
Next, I wanted to look at the frequency of different routes. In the image below, stroke thickness indicates how many trips each route makes. The relationship of the bus terminals with neighbourhoods and the road network can be easily observed. For instance, the north and west of the city have fewer, but more frequent routes. Whereas, the south has more routes with less frequency. Also, nodes in the north and west seem to rely more on the trunk roads than the diversely-connected nodes in the south. One can easily trace the Outer Ring Road, too.
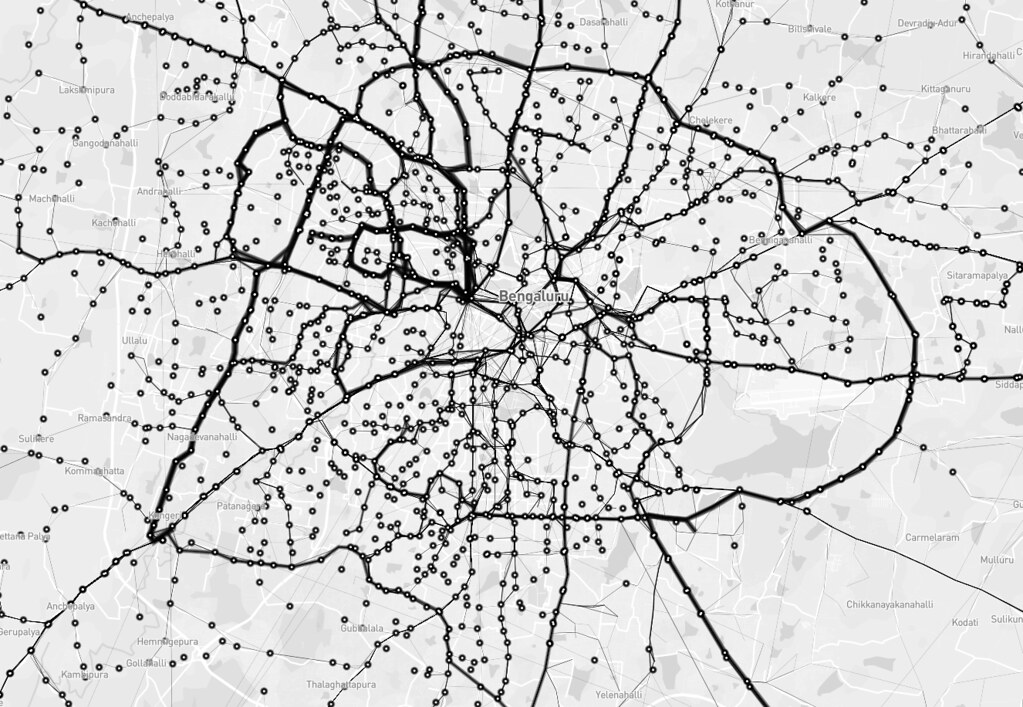
I tried to define reachability as destinations one can get to from a stop without transferring to another bus. The BMTC network operates long and direct routes. The map shows straight lines between bus stops that are connected by a single route. The furthest you can get is from Krishnarajendra Market (KR Market) to the eastward town of Biskuru: roughly 49 km as the crow flies.

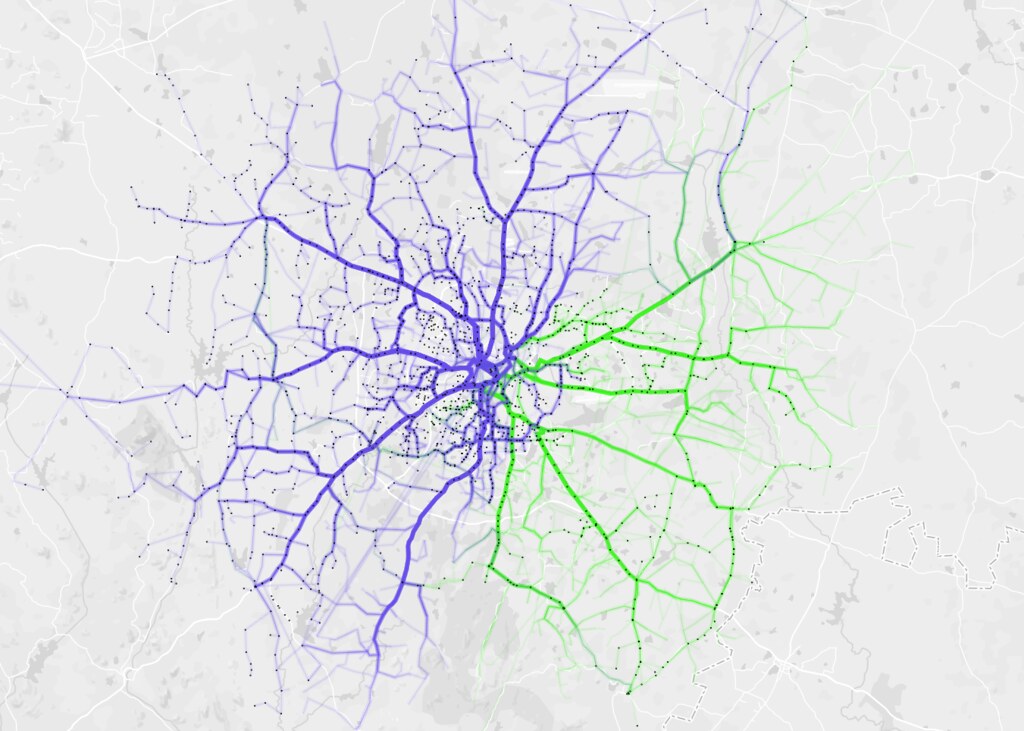
Which directions does BMTC run? It is interesting that BMTC covers the city North – South (blue) and East – West (brown) with almost equal distribution.
BMTC routes are classified into different series. Starting from 1 – 9 and A – W. I analysed coverage based on series 2 (blue) and 3 (green) and they make up almost 76% of the entire network.
Tejas and I took turns to try and figure out the redundancy within the network. Redundancy is good to absorb an over spill of bus commuters. Redundancy is a drain on resources and makes it hard to manage such a vast network with efficiency. So, we looked at segments that overlapped different bus routes.

This map by Aruna shows node strength – number of routes passing through a particular stop. You can see that the strength decreases as we move away from the city center with the exception of depots.

Just like the data, our code and approach are open on Github. We would love to hear from you, and have conversations about the visualization, the BMTC, and everything in between!
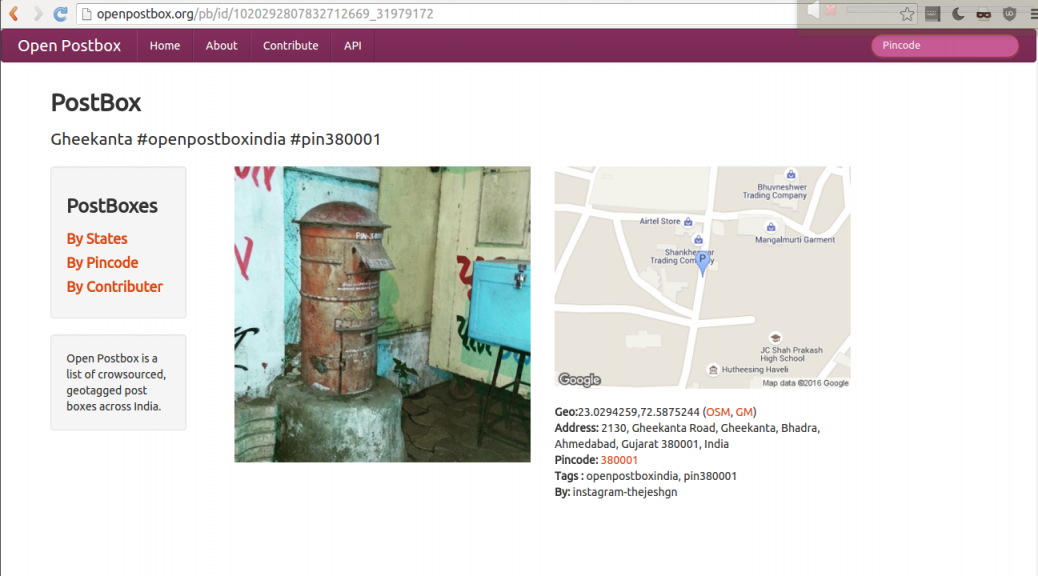
We got a chance to talk to members of Karnataka Philatelic Society about OpenPostBox. They are very interesting set of people. They have also started sending me the postbox pictures using WhatsApp along with location. Now I need to find an efficient way to extract them and insert into my database.
As of now I am thinking of Export -> Parse -> Insert. Working on it. If you have any ideas do email me.

Details of the meet are on my personal blog if you like to read.
Last year I helped assess the water quality section of the Global Open Data Index (GODI). Given the news of lead poisoning in Flint, Michigan and increasingly beyond, safe drinking water is no longer assured even in countries where it’s been guaranteed, so I am very glad they included it in GODI.
GODI is a survey of 122* countries that look at the status of ‘high priority datasets’ and whether they are truly open according to the Open Data Criteria. Water quality was included last year for the first time. So my job was to examine each country’s submission and assess if the data submitted was what was asked for and met the criteria for being open. This was a daunting task but I figured if I could find water quality data in India of all places it wouldn’t be impossible.
Assessment Criteria/Methodology
GODI looked for very specific parameters:
While there are a lot more parameters that could be asked for, these were a good sample of parameters to assess if there is robust water monitoring in the country.
After the initial submission phase there were a lot questions about why wouldn’t the survey just ask for drinking water quality data or environmental monitoring data?
Choosing parameters instead of programmes is important because monitoring the environment and drinking water quality are connected. Some countries haven’t really established large nationalized water treatment strategies, drinking water comes directly from a natural resource so the environmental monitoring data inadvertently applies to the drinking water scenario. Which means that if a country really has robust water quality data they must have these 5 parameters because they cover surface and ground water sources and also reflect safe drinking water standards.
The assessment would be rejected if a submitter only found the surface water body monitoring stations (environmental water monitoring) for instance because arsenic and fluoride are only found in groundwater. So the submitter would either ideally find the treated drinking water quality data which will cover all the parameters or the source water quality data for both surface and ground water.
For a full look at the methodology of the entire survey go here.
Some background
There is no one way to create water management systems but there are two major ways by which people get water – directly from the source or piped in from a source or a treatment facility. The origins of the water source is important. If you are getting water from the ground there are different quality issues than from surface water (lake or river). If water is from a treatment plant there is a possibility that plant is getting water from both surface water, ground water, and in some cases recycled water. Usually water quality is measured at source and after treatment (treatment plants take multiple water quality samples during the treatment process.)
A full water quality assessment means lots of parameters and not all of them are tested the same way; some parameters take several days and require specific conditions, others can be taken easily through filters or litmus papers. Water quality is a deliberate process of sampling and testing, and it not as easy as sticking a sensor into the water and monitor a continuous feed of data (although the potential for these approaches is quickly growing as technology improves.)
What I looked for
Since water quality was a scientific process I figured if I found any proof of water treatment or quality monitoring, a dataset would not be far off. After going through a few countries I noticed that the different water management approaches and policies affected where you would find the data.
Most countries give drinking water treatment responsibilities to local bodies but sometimes is monitored by central government under public health regulation so aggregated data could lie with the public health ministry or the environmental protection body. In most cases responsibility for environmental monitoring fell to a central government Environmental Ministry.
So this scenario means that multiple datasets exist – a centralized dataset for surface and groundwater that usually lies with the environmental ministry that could have all the parameters but sometimes doesn’t, or it doesn’t have real time data (this means data may be available but from less frequent data collection such as quarterly or half yearly efforts). Or the Public Health Ministry has reports of water quality with all the parameters but these are aggregated, and usually in a report form (not a dataset) and not updated in a timely manner.
The US, for instance, falls under this group and can produce confusing submissions. The US has a robust geological survey of surface and ground water sources. However, the drinking water reports are supposed to go to the Environmental Protection Agency but no one seems to be updating the database with information. In my assessment I reduced the score because both are supposed to be available in the public domain.
There are countries like Belgium where water management and monitoring are completely left to the local body and there is no central role for monitoring at all, which meant there is no dataset.
There are countries where there is a strong central role in water management and a dataset could be made open like in France. Korea stood out, because they have live real time water quality information from their treatment plants that gets updated to a website.
Then there are the ‘unsures’: which are countries that seem to treat water to some degree or have national drinking water monitoring programmes but don’t have data online, reports or any mention of data at all. This is not restricted to the developing world. I was very frustrated with several European countries with newspaper articles riddled with reports of how pristine and delicious their water is that don’t have a single public facing dataset.
Take Aways
United Kingdom and the US, both pioneers of the open data movement had terrible water quality data for water treatment, and no effort has been made to bring the data together or make it available in a real time fashion. Also it is not clear to citizens who holds local bodies accountable for not updating their reports, making reports public or finding ways to bring this data into the light so it can be usable. It is no wonder that the US is now on the cusp of a public health crisis.
It is frustrating that the open data movement hasn’t quite been able to reconcile decentralization and local responsibility with national level accountability and transparency. Public health is a national level issue even though local and regional contexts are required for management. How do we push for openness and transparency in systems like this?
In places like India where water quality treatment is largely left to private players and huge populations are not receiving treated water, the need for data to be available, open, and in the hands of central bodies but also local players is a must, because people need to try to find solutions and where to intervene. Given the huge problems with water borne diseases, the slow but epic arsenic and fluoride poisonings gripping parts of India, and the effects this will have for generations, making this data public, usable and demystified is no longer an option.
All in all, I have to say this was an enlightening experience, it was cool to be able to learn something about each country. In our continuous push for open data we sometimes get lost in standards, formats, and machine readability, but taking a moment to really prioritize our values in society and have open data reflect that is essential. Public health outcomes and engaging with complex issues like it are an essential part of how to grow the open data movement and make it relevant to millions more.
*(Correction: Previous version said the survey included 148 countries, the actual number is 122.)
DataMeet has always been interested in doing projects so last year we decided to run a pilot. In the last few years the demand for data work has increased from non profits and journalists and they usually approach data analytics vendors like Gramener. However, these firms can be expensive or have high paying clientele which means that smaller accounts tend to not get their full attention. This leads to an increase in volunteer events like hackathons which don’t always result in finished usable products or can give non profits the long term engagement they need to solve issues. Vendors are not usually privy to the specific data problems a sector has and don’t want to let their tech people invest the time to learn about the subject and understand the particular data challenges. Though the civic tech space is growing, non profits and media houses can’t yet afford or see the need for internal tech teams to deal with their data workload.
With all this in mind we wanted to see if DataMeet can help fill and enrich this space as well as help build capacity within non profits to manage data projects. We were trying to find out, can we assemble teams through the DataMeet network to manage the entire pipeline of data work from clean up to visualization. These wouldn’t be permanent teams but filled with freelancers or hobbyists.
For this first project DataMeet would project manage and Gramener would provde the data analysts, the non profit managing partner was Arghyam and the ground partner was Megh Pyne Abhiyan. Megh Pyne Abhiyan works in several districts in north Bihar on water and sanitation issues. They wanted to use data to tell the story of what the status of water and sanitation was in those districts as a way of engaging with people during the election. It was decided we would do water and sanitation (WATSAN) status report cards for 5 districts — Khagaria, Pashchim Champaran, Madhubani, Saharasa, and Supaul — using government data.
This was an exciting project for us because it would be the first time DataMeet would work with a partner who works on the ground and the output would be for a rural, non online, non-English speaking audience.
DataMeet would project manage the process of data cleanup, analysis and visualization (which the team from Gramener would do) and then give the report cards to the Megh Pyne Abhiyan for them to do the translation and create the final representation of the report cards for their audience.
The Data
The partner wanted the data to be mapped to Assembly Constituencies, they wanted analysis for following situations
It was also important to understand this data in the context of the flood prone areas of Bihar. For instance if there is an area that gets drinking water from shallow wells, with little sanitation in a high flood area those areas can suffer from high levels of water borne diseases.
The data we got was from
Since we were doing report cards based on Assembly Constituencies we needed the data to be at the Gram Panchayat (GP) level. Luckily the MDWS does a good job of collecting data all the way down to habitation so GP level data was available.
There is no official listing of what GPs are in which Assembly Constituency so the partner was asked to split the data by AC so we wouldn’t have to do that mapping. They agreed they knew the area better and would have the resources to pull together all the GP level data into organized Dropbox folders grouped by districts then split into ACs.
Data Cleanup
We received one PDF file per GP, for water access and number of toilets, water quality was given in one large file by district.
All the data we received was in PDF. This was a huge hurdle as the data was from the government information management system so it was from a digital format but rendered in a PDF this meant that we had to convert unnecessarily. However, since the ground partner picked the data they needed and organized it by AC we wanted to make sure we were using the data they specified as important. So we decided to convert the data. This job was done by Thej and I and was extremely manual and time consuming and caused some delay in the data being sent to the analysts. (See how we did it here.)
Analysis
The analysis required was basic. They needed to know at an AC level what the sanitation coverage was, the sources of water, how people were accessing it and what the water quality situation is. Rankings compared to other districts and ACs were done to give context. Rankings compared to other districts and ACs were done to give context.So in all the analysis stage didn’t take much time.
Example of Analysis
Visualization
The UNDP along with the Bihar State Disaster Management Authority had created a map of diaster prone areas including flood. It was in PDF so we asked the folks at Mapbox India to help out with creating a shapefile for the flood map so we layer flood areas onto the Assembly Constituencies.
Bihar AC map with flood prone areas
While we had AC maps we didn’t have GP level maps. They didn’t seem to be available and we couldn’t find them in PDF form either.
Since the election is staggered by district we started with Khagaria. After the initial report cards were done the partner wanted just the cleaned up data in tables to use for their meetings. So we then decided to do the report cards, clean up the data and send the spreadsheets over to them.
As we were processing the next 4 districts I found GP level maps of Bihar, with boundaries of ACs included. This was quite exciting and I thought since we had some time we could do maps for the four pending districts.
After receiving the analysis for the next district I decided that since it would take to long to trace the PDF maps, so the analysts could map the GPs, I would just over lay them onto our AC shapefiles in Photoshop. I was going to put icons or circles in the center of the GP and that would be the map. While tedious I figured it would be worth it to show the maps to the ground partner.
However, when I started mapping I realized that analyzed data wasn’t matching up with the GPs on the map. The GPs listed in the Assembly Constituency in our original folders were incorrect, which meant all the analysis was wrong. Everything had to be checked against the maps and reorganized in the final datasets and then reanalyzed. This caused a huge delay.
On top of that the GPs on the map were spelled differently than in the MDWS data, and every dataset potentially had a different spelling of a particular GP. Which meant the remapping of the data had to be done manually looking at the map, the data, other sources, and sometimes guessing if this was the correct GP or not. This ended up being a manual process for every AC, as we didn’t do this mapping and standardization in the beginning.
While the delay caused problems with the maps being used in the election, they were worth doing to understand the problems with the data and the ground partner identified with the maps the most. By the end we were able to produced districts posters for the different parameters.
Sample report card
Final Posters





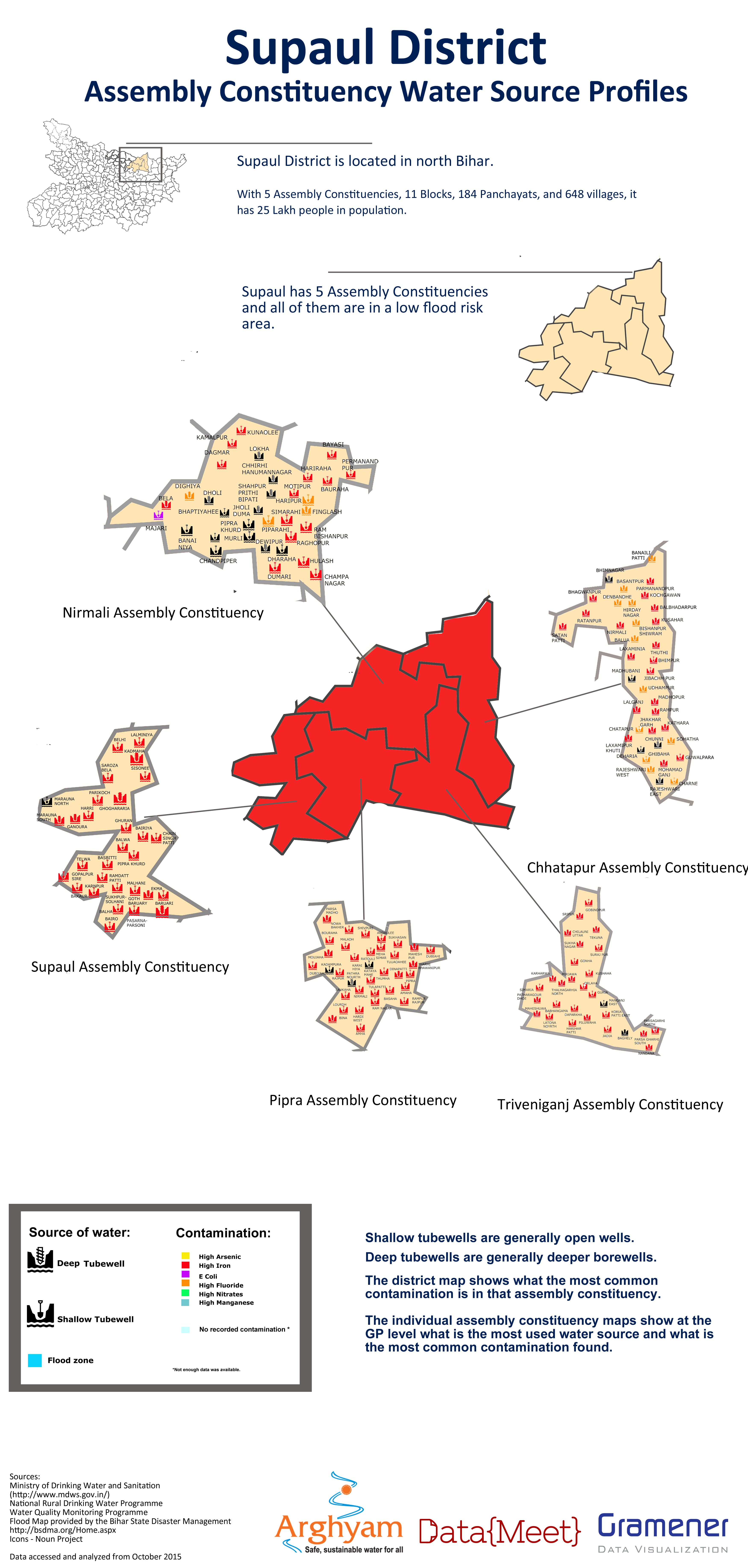
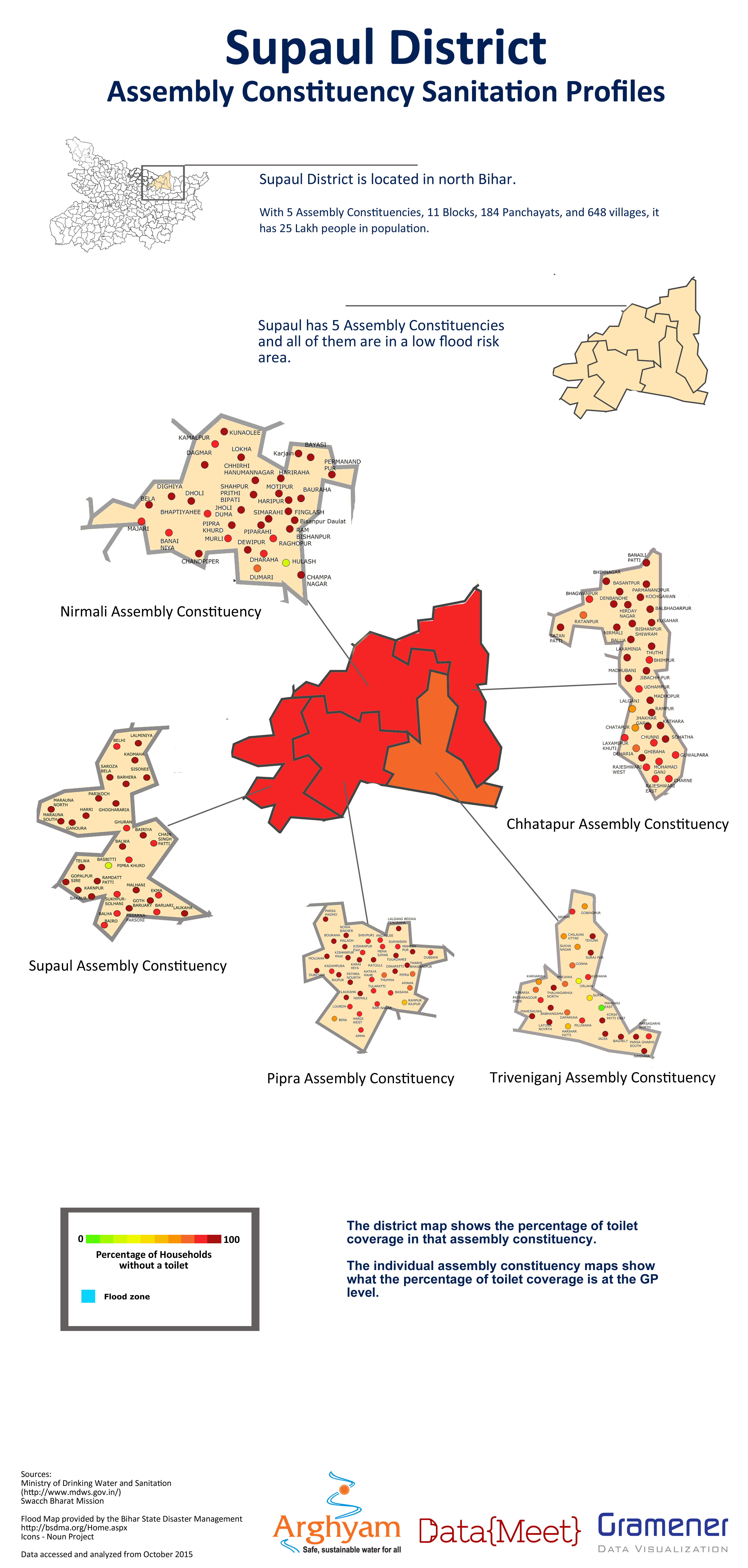





Lessons for next time
We learned a lot from this process. Mainly that the issues with standardization of Indian names in data is a real concern. While initiatives like Data.Gov.In are an important first step, it will take real will and dedication to work out this problem.
NGOs and groups that don’t work with data at the scale of modern data techniques are not always familiar with issues like formats, standardization problems, data interoperability,visualization and mapping to other datasets. This means that more time needs to be spent getting the intentions of the project out of the partner not just outputs. Problems like PDFs are not things everyone thinks about so the extra time of working with the partner to understand what data they want and find way to get it are better spent then converting PDFs to CSV if we don’t have to.
Designers are important, I created and designed the maps and posters, while I’m proud of them, they could have been done better and faster by a trained designer. Designers are worth the money and effort in order to make the final product really reflect the care and work we put into the data.
I consider this experience a success, despite the setbacks, we learned how to manage a team that was not full time and how important the initial work with the ground partners are to create realistic deliverables and timelines.
You can get all the data on DataMeet’s github page.
Big thanks to the Gramener team – Santhosh, Pratap and Girish for dedicating their free time to this.
We consider 26/01/2011 as DataMeet birthday. Thats the day we talked about starting DataMeet and hence it is the birthday. But the first email to the group was sent by S.Anand on 27/01/2011. Its been five years since that first email. I took this opportunity to scrape the email list to see how we are doing and what we talked about in last five years.
Members have started 1525 and have sent in total 4570 emails. But most important is how many participate.

| Category | Members |
| No Emails | 855 |
| 1 Emails | 184 |
| 2 Emails | 75 |
| 3 Emails | 43 |
| More than 3 | 189 |
Go have a look at full view of the traffic graph. Except for few peaks the group has been fairly consistent.
We have discussed about 1525 in last five years. Here is the list of top 20 starters.
| author | total topics started |
|---|---|
| Nisha Thompson | 199 |
| Thejesh GN | 164 |
| sumandro | 71 |
| Sridhar Gutam | 64 |
| srinivas kodali | 36 |
| Gautam John | 30 |
| Sajjad Anwar | 28 |
| Pranesh Prakash | 27 |
| bawaza…@gmail.com | 27 |
| Venkatraman.S. | 23 |
| satyaakam | 22 |
| S Anand | 21 |
| Balaji Subbaraman | 20 |
| Nikhil VJ | 19 |
| Justin Meyers | 15 |
| Sanky | 15 |
| Dilip Damle | 14 |
| Maya Indira Ganesh | 13 |
| Shree | 13 |
The first responders are important when someone posts a question. They are the first ones to respond to the questions. As you would have guessed the list is different from the starters list.
| author | number first response |
|---|---|
| Devdatta Tengshe | 36 |
| Gautam John | 36 |
| Nisha Thompson | 57 |
| srinivas kodali | 28 |
| Thejesh GN | 27 |
| Sajjad Anwar | 21 |
| satyaakam | 20 |
| Arun Ganesh | 16 |
| Avinash Celestine | 15 |
| Venkatraman.S. | 15 |
| Anand Chitipothu | 14 |
| sumandro | 13 |
| Dilip Damle | 10 |
| JohnsonC | 10 |
| S Anand | 10 |
| Gora Mohanty | 9 |
| Meera K | 9 |
| Sabarish Karunakar | 9 |
| Nikhil VJ | 8 |
These are the members who have participated the most.
| author | total_emails_sent |
|---|---|
| Nisha Thompson | 397 |
| Thejesh GN | 297 |
| Gautam John | 158 |
| srinivas kodali | 128 |
| sumandro | 109 |
| Sajjad Anwar | 93 |
| Arun Ganesh | 88 |
| Dilip Damle | 88 |
| Devdatta Tengshe | 85 |
| satyaakam | 83 |
| Sridhar Gutam | 81 |
| Avinash Celestine | 73 |
| Justin Meyers | 71 |
| S Anand | 68 |
| Pranesh Prakash | 67 |
| Venkatraman.S. | 64 |
| Nikhil VJ | 55 |
| Raphael Susewind | 55 |
| Anand Chitipothu | 51 |
We have discussed many many topics over years. But there are some popular topics. I have the list of topics by most replies.
| Starter | date/time | topic |
|---|---|---|
| Karthik Shashidhar | 2015-05-04 23:00:01 | Shapefiles for "complete" India |
| megha | 2014-04-10 14:10:21 | MP/MLA Shapes |
| Srihari Srinivasan | 2013-03-06 22:59:44 | List of BMTC Bus stops |
| Nisha Thompson | 2014-05-20 23:51:49 | Logo Contest Voting! |
| S Anand | 2016-02-01 18:31:38 | PIN code geocoding |
| Siddarth Raman | 2014-04-17 16:16:29 | Parliamentary Constituency to Assembly Constituency to Ward linkages |
| Nisha | 2013-04-15 09:44:21 | April's Bangalore DataMeet |
| Gautam John | 2012-04-14 09:49:50 | I Change My City |
| Arun Ganesh | 2011-03-14 11:23:25 | Licensing crowdourced data projects |
| Sharad Lele | 2015-11-27 19:59:49 | Census of India seems to have maps of everything! |
We also get quite a bit of traffic through search engines. So here is the list of top topics by views.
| username | date_time | views | topic |
|---|---|---|---|
| Karthik Shashidhar | 2015-05-04 23:00:01 | 12324 | Shapefiles for "complete" India |
| S Anand | 2016-02-01 18:31:38 | 4783 | PIN code geocoding |
| srinivas kodali | 2013-07-01 12:49:33 | 2291 | GeoJson data of Indian states |
| Aashish Gupta | 2014-02-24 10:23:12 | 763 | 1981 and 1991 district-wise census data |
| Justin Meyers | 2014-07-26 22:05:13 | 668 | Updated Taluk Shapefile!! |
| indro ray | 2013-08-13 10:21:18 | 651 | MCD Delhi Admin Boundary GIS map |
| My profile photo | 2012-08-30 17:41:45 | 615 | Bangalore – BBMP ward boundaries – shape files available now |
| megha | 2014-04-10 14:10:21 | 556 | MP/MLA Shapes |
| Kavita Arora | 2012-09-13 23:32:25 | 546 | Ward Wise data for Bangalore – 2011 census? |
| Renaud Misslin | 2014-12-03 09:45:16 | 426 | Delhi ward shapefile for census 2011 data |
At last customary wordcloud of topics.

Of course all the scrapers and data is available on github. Go ahead make your own visualizations.
-article by Rasagy Sharma
On the 16th of January, we hosted the fifth Datameet event for the Pune chapter at the Symbiosis School of Economics. The focus in this event was more on enabling discussions and initiating collaboration, so a Roundtable format was selected with three main speakers: Padmaja Pore from Door Step School, Jinda Sandbhor from Manthan Adhyayan Kendra and Nikhil VJ (Centre for Environment Education).
The session started with everyone introducing themselves. After that, Craig — co-organizer of the Pune chapter — talked about what Datameet is, how it started, and the aim of city chapters. He then explained how the Pune chapter is focused on connecting data-enthusiasts from various disciplines — such as NGOs, Data Analysts, Engineers and Designers — to help collaborate and spread more awareness about how data can be used.
The roundtable started with Padmaja Pore introducing Door Step School, an NGO that runs several projects around primary education. One such project is Every Child Counts (ECC) that was started in 2011 and focused on ensuring that every child goes to school at the right age of 6-7 yrs. Through ECC, Door Step School seeks to understand and address barriers to the schooling of kids of migrant communities such as those engaged in nomadic professions,workers at construction sites, factories, brick-kilns, etc. in the vicinity of Pune city. When parents move their home several times in a year itself, how can it be ensured that their kids remain enrolled in schools?
In India, there are more than 1 million kids out of school (18 million in Southern Asia and 69 million globally). The Right to Education Act has ensured that free and compulsory education is available, but no systematic process of finding and enrolling out-of-school not been actively implemented, with no definite count of the number of migrant children denied education. Surveys have been focused on children already working/street children, whereas the need is to focus on children who are 6-7 years old so that they are enrolled into schools before they get drawn into employment. There have been no active steps to put in processes at schools for ensuring migrant children can transition smoothly to another school when they migrate. .
The ECC Project has the following Implementation Methodology, which is volunteer driven
1. Surveys: Volunteers conduct surveys of construction sites in partnership with NGOs
2.Preparatory camps: Through the medium of preparatory camps, awareness is spread amongst parents of children on the importance of schooling. After working with the children, the team realized that these kids are not aware about the concept of formal education, and are not used to sitting at one place for a few hours to study. Thus the focus in the preparatory camps is on interactive activities to get kids more accustomed to the environment.
3.Admission/ Enrollment: The children and parents are accompanied to a local public school and assisted with the enrolment process. Parents are made aware of the provisions of the RTE act.
4.Support and Follow-up: Arranging transport to school wherever needed, tracking attendance and addressing reasons for non-attendance
The ECC project is currently running in Pune, Pimpri Chinchwad, Fringe areas of Pune & Nasik. The project uses various types of data:
Data sources: http://schoolreportcards.in/SRC-New/ & http://www.dise.in
Currently the data is collected using a mobile app based on ODK (Open Data Kit) & KoboToolbox/ONA. The team is developing a Web based Platform for scaling the ECC Program pan-India and engaging NGOs and CSR groups in this cause. One of the key features of this Website is envisaged to be to engage volunteers actively with children to help motivate, enroll and track their continuity for larger impact.
Padmaja then talked about the way forward and the challenges they were facing w.r.t developing the ECC Platform as well as actually reaching all children in the project areas.
After the talk, everyone pooled in with their ideas and suggestions such as connecting with Trekking communities to pair up as volunteers to reach out to any schools/kids on the outskirts of the city, and collaborating with initiatives like Sagar Mitra (Recycling plastic). Few problems were taken up by individual attendees for further discussions, like finding ways to automate the data entry into excel which is done manually right now. Interested attendees were requested to volunteer and also reach out to their community to spread the word.

For the second talk, Jinda Sandbhor from Manthan Adhyayan Kendra spoke about village level mapping of tanker water supply in Maharashtra. With 14,708 drought affected villages in 2015 and 148 drought prone blocks, there is an immediate need for collecting data to analyze the reasons for drought and what can be done to better prepare for the future.
Most villages facing drinking water shortages due to lack of piped
water supply or lack of drinkable ground water. For such villages,
there is a tanker water supply from the Maharashtra government. The shortages are most severe just prior to and during the monsoon, some of these villages get return (North East) monsoons which reduces the demand of tankers by the end of the year. Jinda showed some aggregate data that has been collected that shows blockwise, the number of villages requesting the tanker supplies during
various months in the past few years.
There are multiple reasons for the demand of tankers:
Jinda highlighted his efforts to collect village specific data in some districts on the reason for request of the tanker. He mentioned that there is need for a village-level base map for Maharashtra that can help visualize and analyze this issue.
The discussions after this talk were focused on GIS related topics, with everyone agreeing for the need for detailed village level maps. While there are village level maps available in PDF as well as as a Web Map Service by Bhuvan, these need to be converted into shapefiles so they can be used for further analysis. This will enable visualizing with great accuracy, not just drought related data but any number of socio-economic parameters of Maharashtra for analysis.
It was also recommended to connect with Prof. Ashwini Chhatre from Indian School of Business (ISB) who has been working on Millets & Irrigation data and would have more detailed maps of the state. Another suggestion was to use GIS to take Land Revenue maps and convert into public-domain data.

The third talk was by Nikhil VJ who is the co-organizer of the Pune Datameet chapter and has been working on multiple data-centric projects. He also showed his work on cleaning and mapping Pune’s Budget sheet, which was originally available as a 600 page PDF and now has been converted to excel and cleaned up considerably. The Pune Municipal Corporation has now agreed to bring in some reform in its budget book format and Nikhil & CEE are working on possible ways to take such tasks forward. Nikhil also covered several tools and methods described below that are easy for anyone to pick up and can help solve some interesting data-related problems.
Some of the resources mentioned by Nikhil were:
The newly launched website www.sahbhag.in — Participatory Urban Governance in Pune
nikhilvj.cartodb.com — Maps & Datasets of Pune posted online by Nikhil
www.crowdcrafting.org — Collecting & mapping of data with the power of crowdsourcing
Localizing Pune’s budget data by Nikhil & other volunteers:
http://crowdcrafting.org/project/localpunebudget
Map form — An experimental method that Nikhil has craeted to collect location data using WordPress plugins
www.mapwarper.net — Using maps that are currently as an image to wrap on
an actual map
With this, the session was formally concluded.







{kind=link}