Over the last few months I went deep-dive into a project with WRI (World Resources Institute) and Kochi Metro in Kerala (KMRL) to convert their scheduling data to the global standard static GTFS format.
The first phase of the project was about just the data conversion. I wrote a python program that took in KMRL’s data files and some configuration files, and created a static GTFS feed as output. There were many more complexities than I can share here, and Shine David from KMRL was a crucial enabler by being the inside man sharing all necessary info and clarifications.
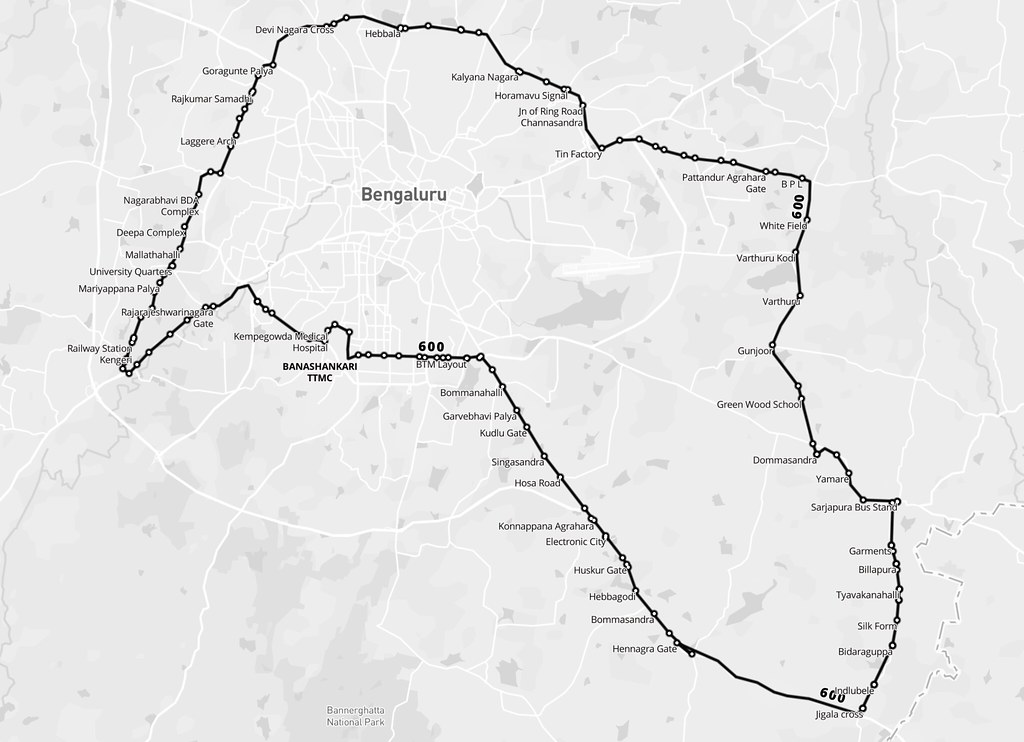
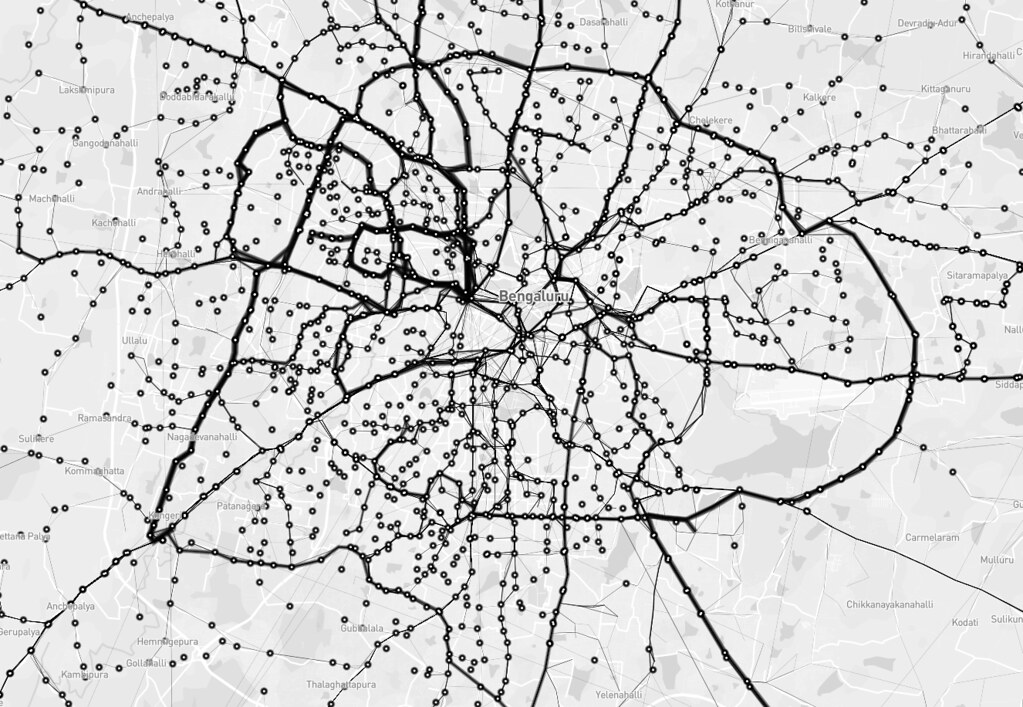
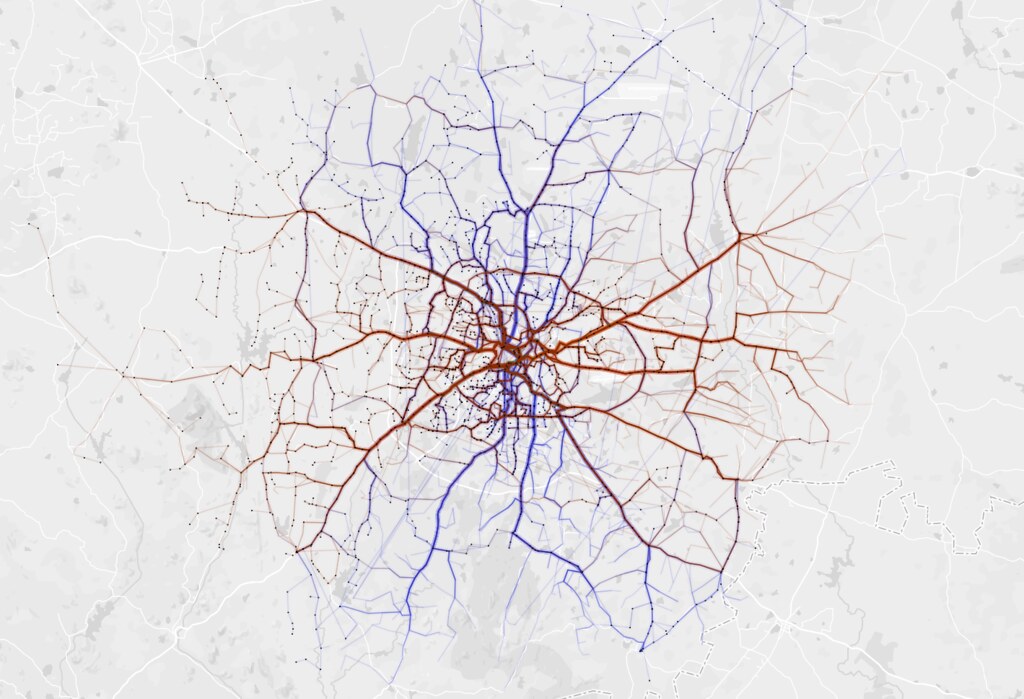
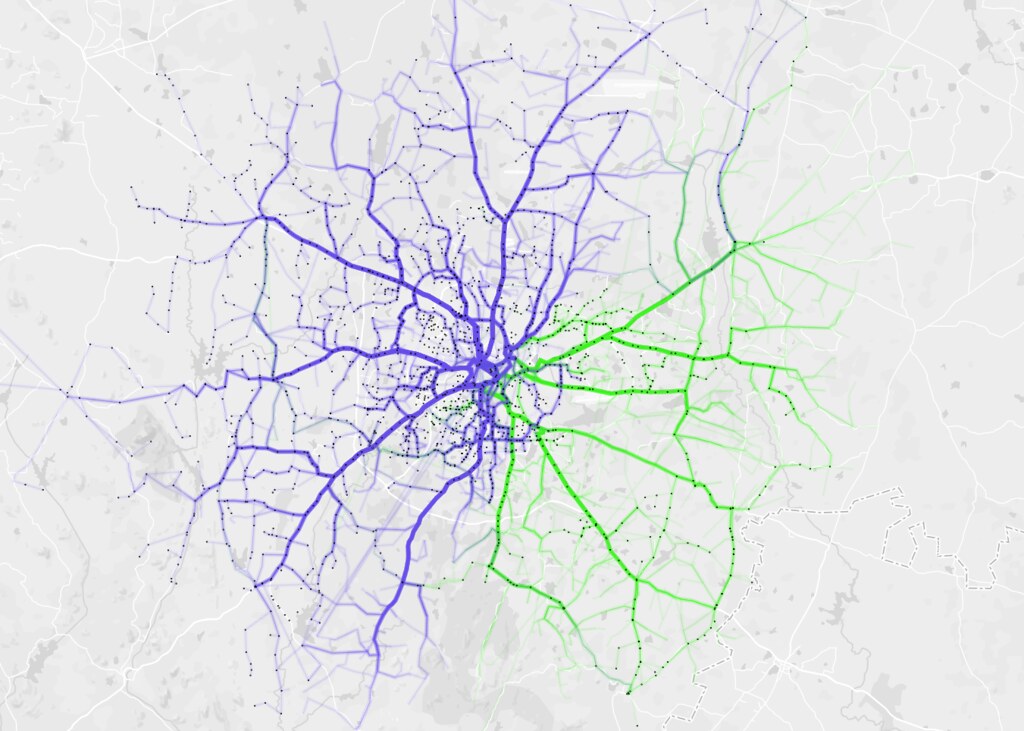
On 17 March this year, Kochi Metro Rail Ltd became India’s first transit agency to publish static GTFS feed of their system as open data.
See the KMRL open data portal and some news coverage: 1, 2, 3, 4.
See it visualized on a global GTFS feeds map called TRAVIC.
(zoom in to kochi and press fast forward. Can adjust time of day.)
Phase 2 of the project aimed higher : we started work on a program with a graphical user interface that would automate several manual processes and help KMRL update their data as the network grows, publish updated feeds on their own without having to rely on any external entity, and very importantly for their case, integrate bus and ferry routes of Kochi in the near future to build towards a unified public transport dataset and facilitate integrated ticketing. As we progressed into this we realised the potential this can have if we generalise it so that any transit agency can use it.
So, here’s launching..
https://github.com/WRI-Cities/static-GTFS-manager

Did I mention we have open sourced the whole thing? Big Kudos to WRI and especially Vishal who co-ordinated the whole project, for being proactive and pro-open-source with this.
The program runs in the browser (actually, please use Chrome or Chromium and no mobile!) as a website with a server backend created by a Python 3 program. It manages the data in a portable internal database and publishes fresh GTFS feeds whenever wanted.
To play around with a live demo version of the program online, contact nikhil on nikhil.js [at] gmail.com
Note: while it’s compatible to publish this program on a free heroku account, it is currently not designed for multi-user use. That’s kind of not in the basic requirements, as end user is just a transport agency’s internal team. (With your participation we can change that.)
So, why I am sharing about this here: Apart from obviously sharing cool stuff,
With this it’s possible to design any transport system’s static GTFS feed from scratch, or edit an older feed you have lying around and bring it up to date.
Invitation for Collaboration
There is more that can be done with enhancements and integrations, and there are still some limitations that need to be resolved. I’m documenting all I know in the issues section. So I’m reaching out for inviting collaborations on the coding and beta testing front. One motive behind open sourcing is that the community can achieve far more with this project than what any private individual or group can. There’s also scope to integrate many other GTFS innovations happening. Please visit the github repo and engage!
Lastly, big shout-out to DMers Srinivas Kodali from Hyderabad chapter for connecting and lots of guiding, and to Devdatta Tengshe from Pune chapter for helping me learn asynchronous server setup in Python in a lightning fast way (with a working example for dummies!)
Quick links:
– static-GTFS-manager
– https://developers.google.com/transit/gtfs/reference/