OpenRefine is a powerful open source tool for working with messy data, made for non-coders. And just to stress on something I don’t want readers to miss,
made for non-coders.
It has a ton of features and I have not had the chance to use and learn the vast majority of them. But I learned one thing so I’m going to share that particular implementation: reconciling spelling differences in data.
Background
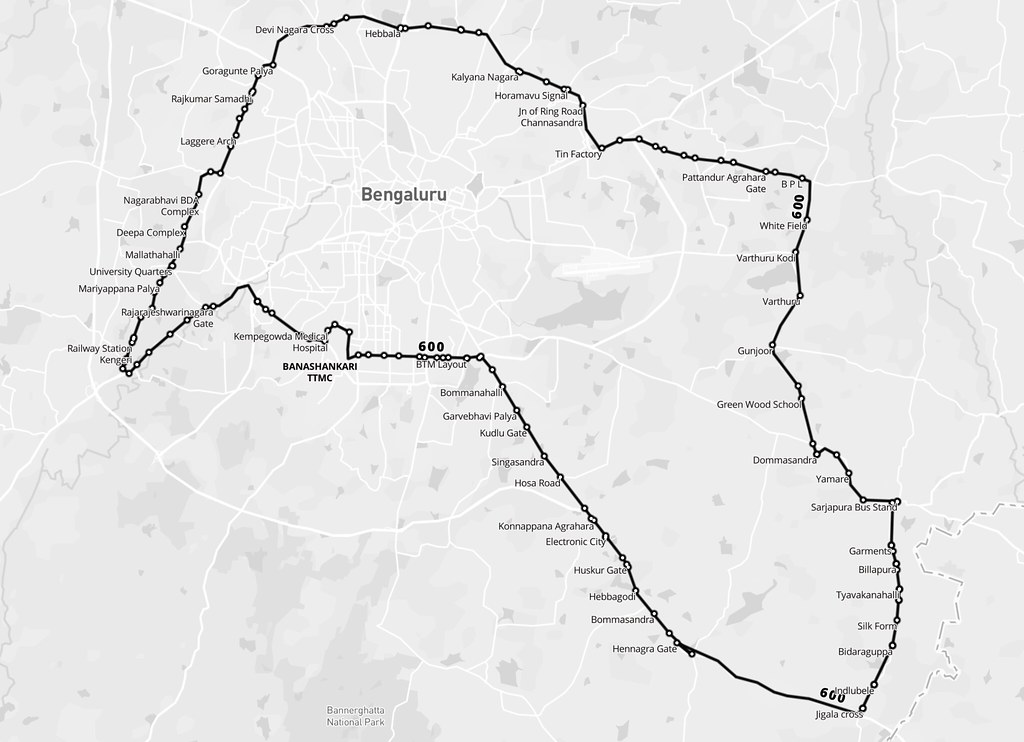
The data that I worked on: a few worksheets having bus stop names from BRT & Non BRT Route Details & Bus Stop LatLong.xls from Pune Open Data Portal.
I’ve written a detailed log of the whole (incomplete) exercise here, but I’ll expand on just the OpenRefine part. Apologies if any of this gets confusing.. just see the screenshots!
Steps
1. All the names that need reconciling are brought under one column. Other columns are kept to track serial numbers, etc. If two or more data tables are involved then a combined table is created carrying columns from all the tables, and one more column is made to disambiguate which sheet the row is from.
2. A copy column is made of this names column in the same table. Just in case we screw up and need to revert. Always make backups!
3. Save the file and load it up on OpenRefine. (assuming that you have downloaded, installed /extracted and started up OpenRefine and it is loaded on a tab in your browser)
4. Now we see the table laid out. There are drop-down arrow buttons on each column heading leading to menu of actions to do on that column. Locate the Names column you want to work on and open its menu.
5. First things first: clean up the cells by trimming leading and trailing whitespaces.

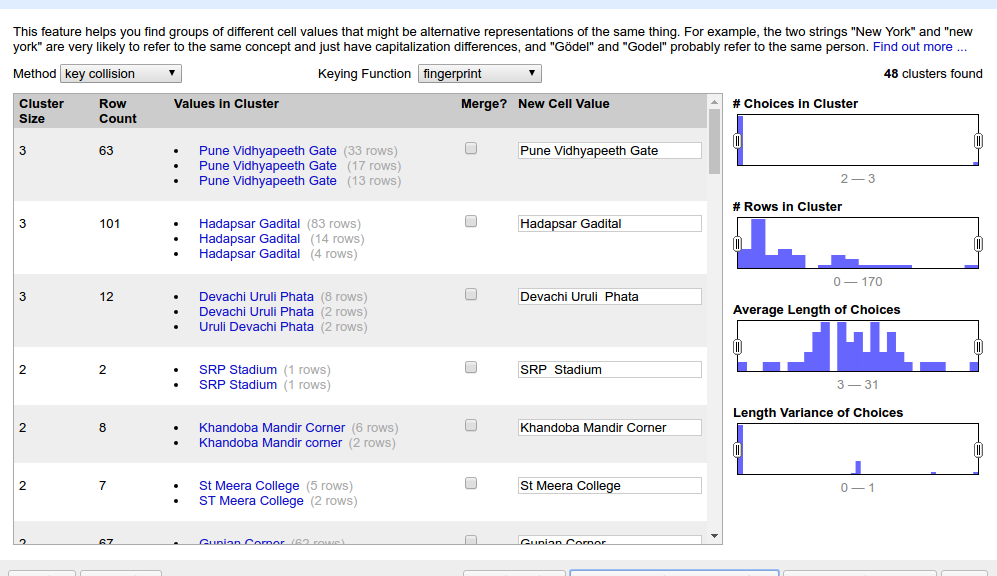
6. Open the column’s menu again and choose Text facet > Clustering on the target column. It should open up something like below. (click the screenshot to see full size)
7. Consider first listing as example. ‘Pune Vidyapeeth Gate’ has 3 different spellings spanning 63 rows. If we click on one of the spellings, it appears under “New Cell Value”. We can even type a whole new spelling. Select the checkbox under “Merge?” and press the big button at bottom “Merge Selected & Re-Cluster”.
8. What happens in the background: The rest of the table stays as-is. But these 63 cells are over-written with the single new value.
9. So in two clicks we have done what normally would be a very long process in excel of filtering, sorting, copy-pasting and restoring to original order.
10. Here is a saved diff check on diffchecker.com that shows on left my original list and on right the normalized list I got through OpenRefine.
11. Do explore the various other options on the page. For bringing similar-spelling words together, certain linguistic algorithms are used (apologies but I haven’t bothered digging deeper into them), and there are multiple options, seen at the top of the last screenshot (“Method”, “Keying function”). Depending on your data one way may work better than the other. You can do one run of clustering / normalizing and then choose another algorithm that might cluster in another way. There will be false positives too (ie names that are supposed to be different only but the program thinks they should be same) and you can ignore them by keeping their “Merge?” checkbox off.

12. One more thing: This program works just as well on other languages. And it is particularly useful in catching all the cases where there’s confusion between choti ee maatra and badi ee maatra:

Bus yaar
So that’s it for this walkthrough. Gratitude to DMer Aravind from Bangalore for insisting I check out this tool when I was saying “it’s ok I’m doing it in excel”. Have you used OpenRefine too? What was your application? Do share here or drop me an email on nikhil.js [at] gmail.com.
Links
- OpenRefine.org – main page has good videos to get you started.
- A collection of quotes said about OpenRefine
PS: No, I’m not going to explain why in the world I was having a table of 40,000+ rows of bus stop names. It’s too traumatizing to share, please understand 😛