Project by Shailendra Paliwal and Kashmir Sihag
Note: This blog post was written by Shailendra
I want to share a 3 year old project I and my friend Kashmir Sihag Chaudhary did for Jaipur Hackathon in a span of 24 hours. It is called Know Your MP, it visualizes data that we know about our members of parliament on a map of Indian Parliamentary Constituencies.
A friend and a fellow redditor Shrimant Jaruhar had already made something very similar in 2014 but it was barely usable since it took forever to load and mostly crashed my browser. My attempt with Know Your MP was to advance on the same idea.
The Dataset
Election Commission of India requires that every person contesting the elections fill an affidavit and therby disclosing criminal, financial and educatinal background of each candidate. There have been a few concerns about this, a major one being that one could as well enter misleading information without any consequences. If you would remember the brouhaha over education qualifications of Prime Minister Modi and the cabinet minister Smriti Irani, it started with what they entered in their election affidavits. However, it is widely believed that a vast majority of the data colllected is true or close to true which makes this a dataset worthy of exploration.
However, like a lot of data from governments, every page from these affidavits are made available as individual images behind a network of hyperlinks on the website of Election Commission of India. Thankfully, all of this data is available as CSV or Excel Spreadsheets from [MyNeta.info](http://myneta.info/). The organization behind MyNeta is Association of Democratic Reforms(ADR) which was established by a group of professors from Indian Institute of Management (Ahmedabad). ADR also played a pivotal role in the Supreme Court ruling that brought this election disclosure to fruition.
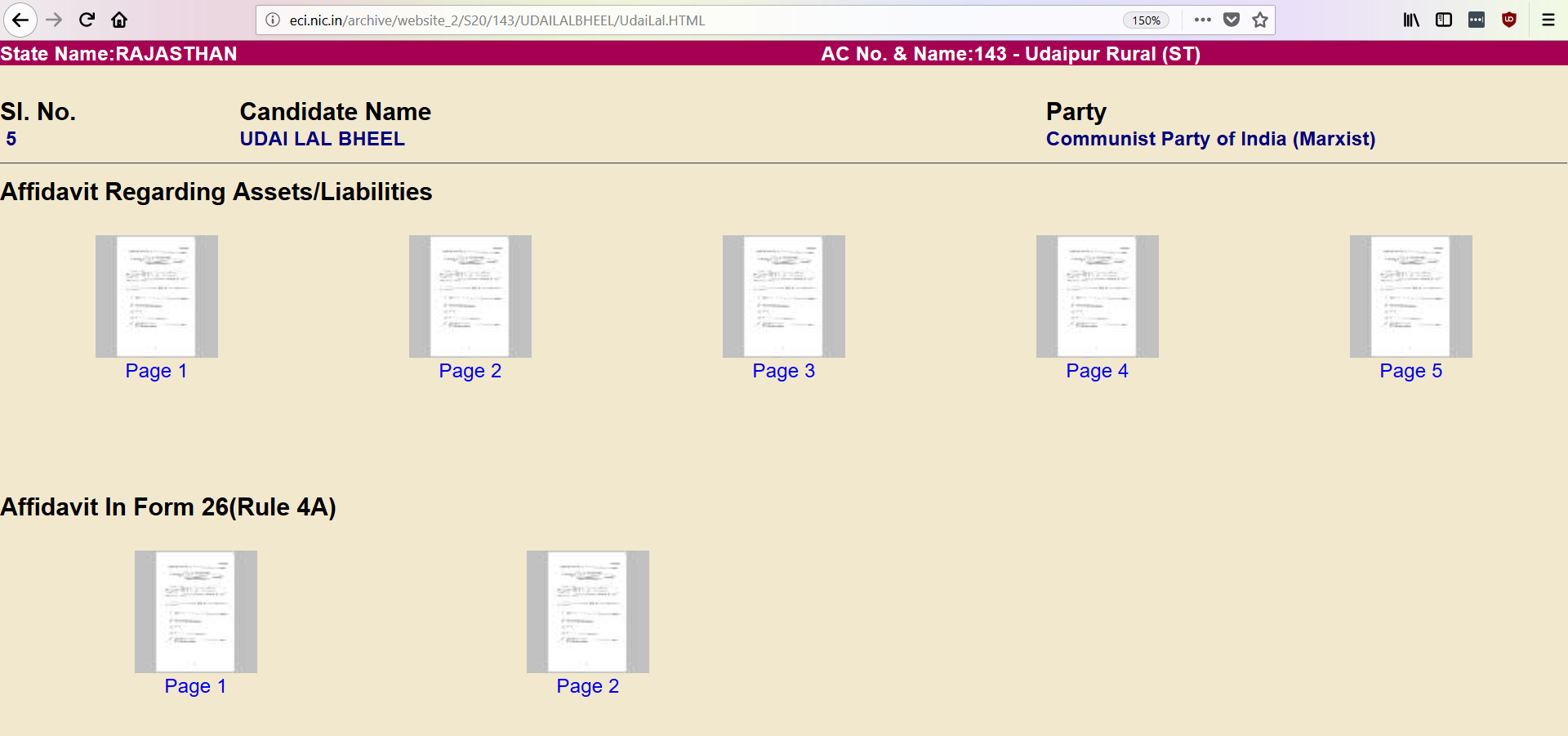
Cadidate Affidavit of CPI(M) candidate Udai Lal Bheel from Udaipur Rural constituency in Rajasthan. link
Preparing the Map
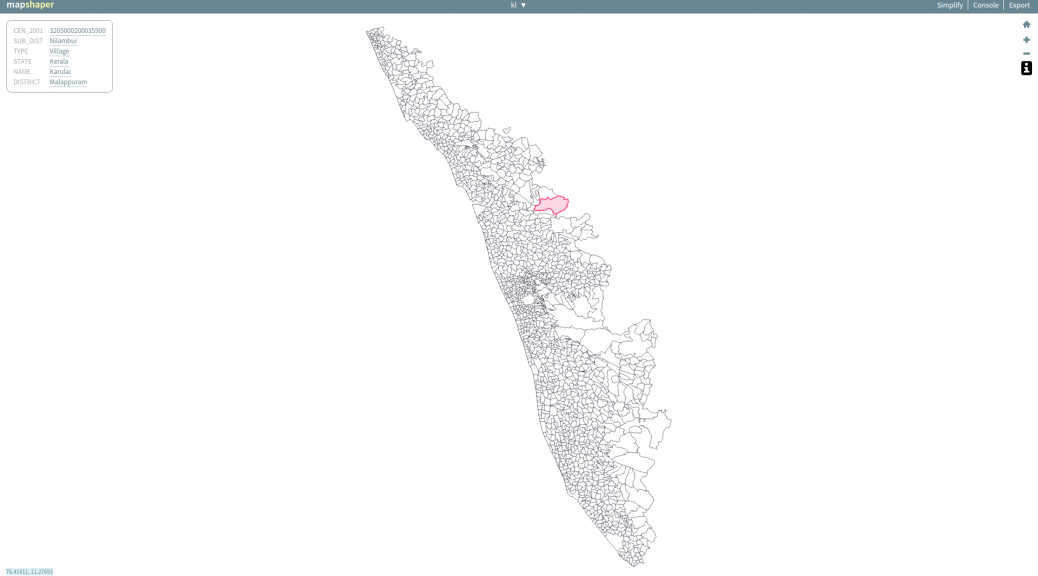
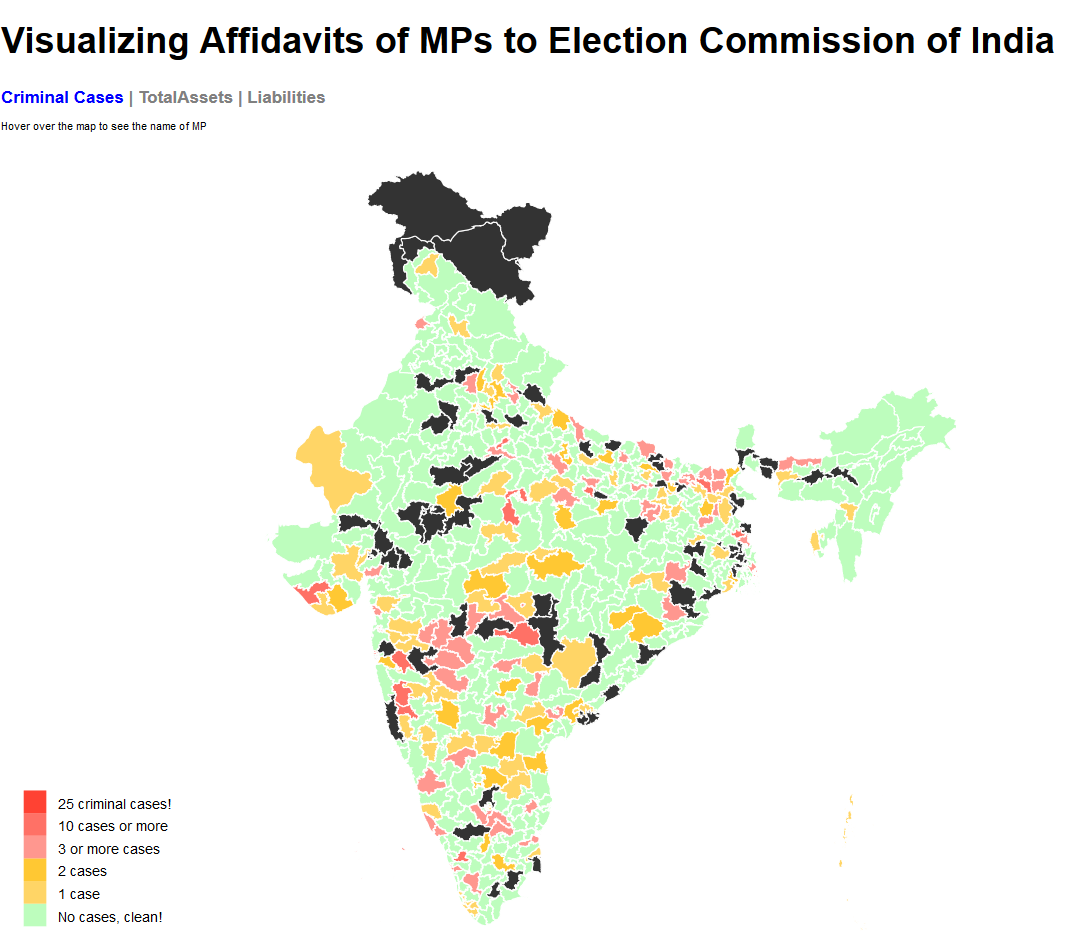
This data needs to be visualized on a map with boundaries showing every parliamentary contituency. Each constituency will indicate the number of criminal cases or assets of their respective MP using a difference in shading or color. Such visualizations are called choropleth maps. To my surprise, I couldn not find a map of Indian parliamentary constituencies from any direct or indirect government sources. That is when datameet came to my rescue. I found that DataMeet Bangalore had released such a shapefile. It is a 13.7MB file(.shp). Certainly not usable for a web project.
Next task would be somehow compress this shapefile to a small enough size that can be then used either as a standalone map or as an overlay on leaflet.js or Google Maps (or as I later learned Mapbox too).
From the beginning I was looking at d3.js to achieve this. The usual process to follow would be to convert the shapefile (.shp) into JSON format which D3 can use.
For map compression I found that Mike Bostock (a dataviz genius and also the person behind D3) has worked on a map format that does such compression, the format is called GeoJSON. After a bit of struggling with making things work on a Windows workstation and tweaking around with the default settings, I managed to bring the size down to 935 KB. Map was now ready for the web and I now had to only wade through D3 documentation to make the visualization.
Linking data with map and Visualization
Each parliamentary region in the GeoJSON file has a name tag which links it to the corresponding data values from dataset. A D3 script on the HTML page parses both and does this job to finally render this choropleth map.
The black regions on the maps are parliamentary contituencies that have alternate spellings. I could have used levenshtein distance to match them or more simply linked the map to data with a numeric ID. I’ll hopefully get that done someday soon.
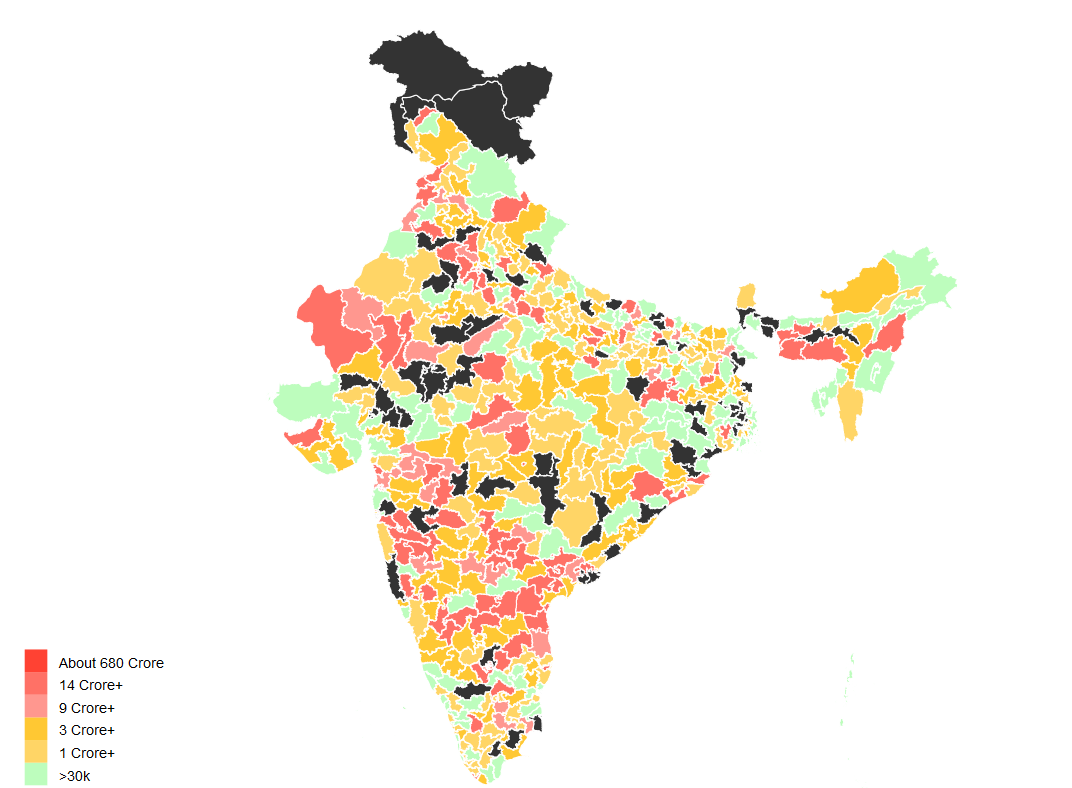
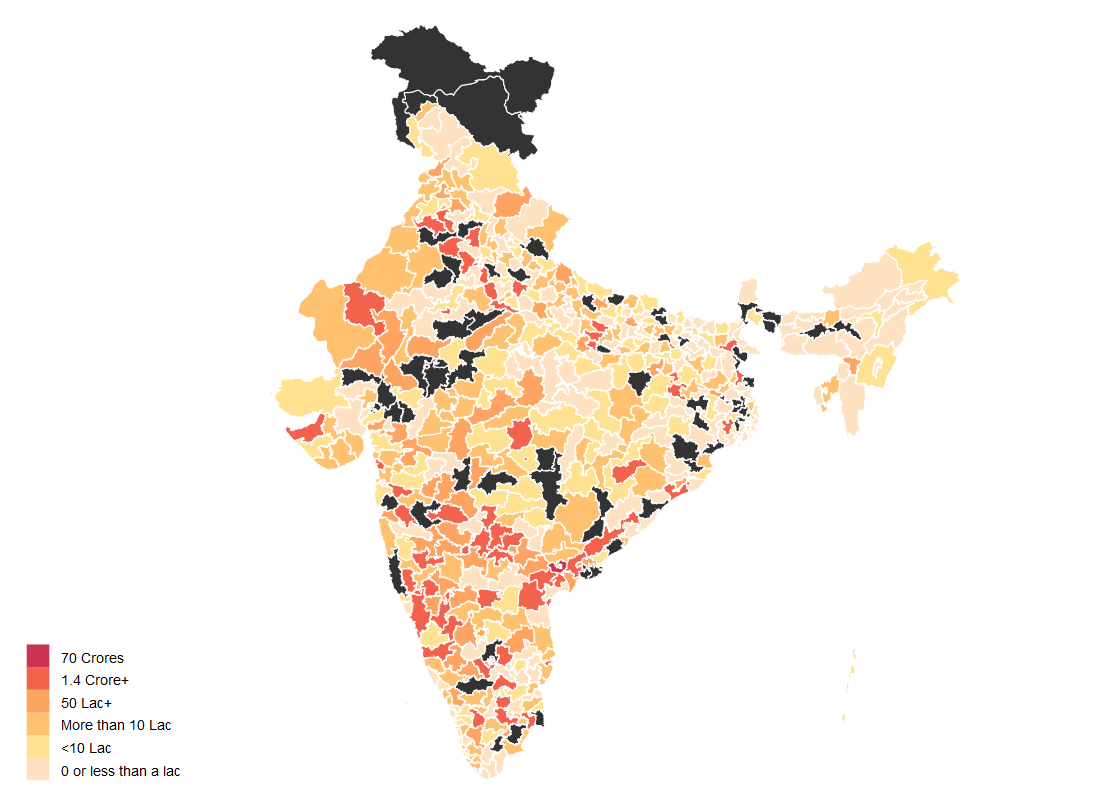
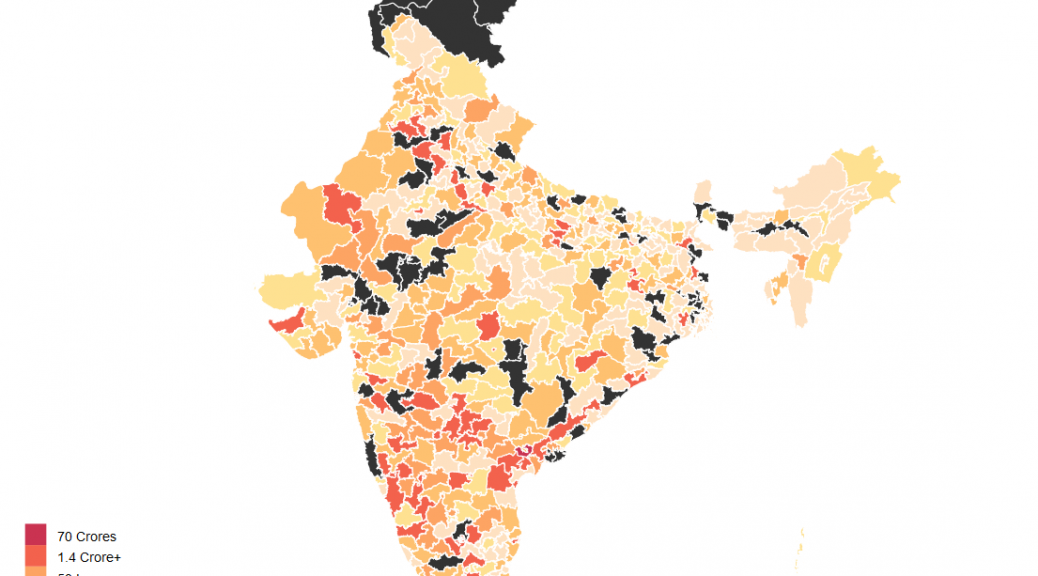
Finally Looking at Data
The average member of parliment (only a few MPs have changed since 2015) has at least 1 criminal case against them, has a total asset value of about 14 Crore INR and has liabilities of value 1.4 Crore INR. But this dataset also has a lot of outliers so mean isn’t really the best representative of the central tendency. The median member of parliament has 0 criminal case against them, has total assets worth 3.2 Crore INR and has liabilities of value 11 Lakh INR.
The poorest member of parliament is Sumedha Nand Saraswati from Sikar who has total assets worth 34 thousand INR. Richest MP on the other hand is Jayadev Galla with declared assets of 683 Crore INR. Galla doesn’t directly fit the stereotypical corrupt politician meme with zero criminal cases against him. His wealth is best explained to the success of lead acid battery brand Amaron owned by the conglomerate his father founded in 1985.