TL;DR : Wanna survey without paperwork headache? Check out ODK and Ona.io when you get the time.
A] ODK-1
ODK or Open Data Kit has been an important tool that made mobile-based survey data collection with complicated forms etc possible. Their XLSForm structure where the form is created in excel (!) is arguably more feature-packed than most online survey tools, and comes somewhere between coding and non-coding. It has companion websites like Ona.io that take care of server-side things and enable folks to get started with on-field data collection with zero overhead costs. Being open-source and entrepreneur-friendly, a lot of enterprise services in this sector are actually running on the ODK base and have customized it to suit specific needs.
My experience with ODK:
1. I have guided a team member each about this in two NGOs in Pune: CEE and Grammangal, with just the setup and getting started, a couple of years back, and I have seen them deploy and take this forward far beyond my expectations. I would recommend other NGOs who want to do this to consult them for a peer-to-peer exchange : they’ll speak in your language! (Marathi? Even more so!)
2. I have also briefly taught about it to some interns from a social sciences college (major CV value-add bro!),
3. and in a crash course workshop for some governance Fellows on practical mapping/survey techniques.
4, But as of now I haven’t myself participated in a complete survey exercise using ODK.
ODK community has a cool discussion forum, where people can post queries. The majority or users and consequently deployers of ODK are more from social sciences background than coding background, so the forum is quite helpful and newbie-friendly.
B] Feedback
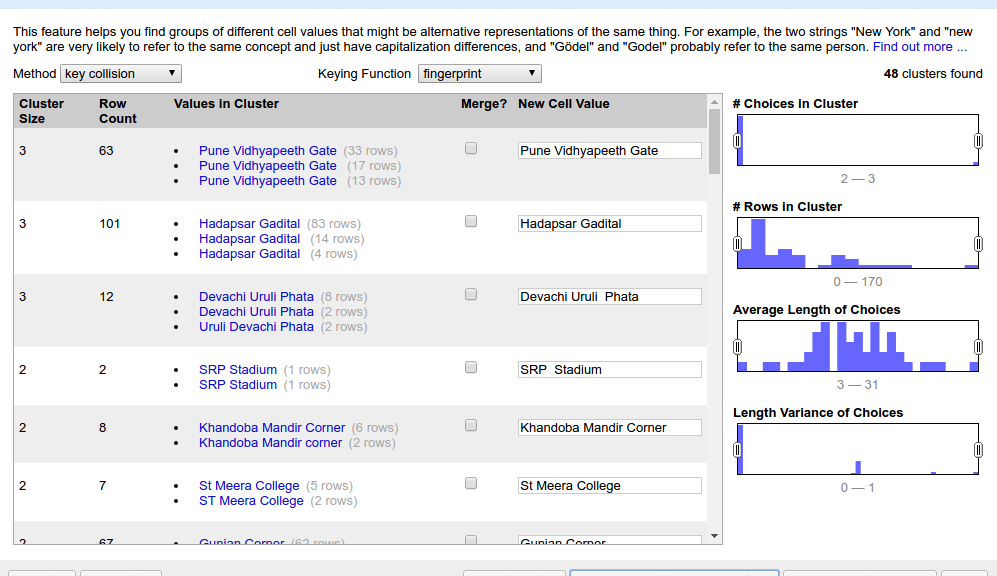
One regular feedback coming with the ODK tool has been about the one-way nature: If you have one project with 12 people on-field sending in data, it’s a hub-spoke model and the 12 people can’t easily check what the others have posted. They can’t even retain on phone the data they themselves collected once they have submitted it to “HQ”, and so it’s difficult for team members to keep track of things and stay in the loop, especially if they’re in remote areas or on the move and can’t get online on a laptop to inspect the collected data, or cases where the field agent is comfortable operating the phone app (multilingual btw) but not the laptop. (did I mention, you can operate ODK in zero network coverage and sync things with HQ at the end of the day / outing when you get back in range or climb up the roof or tie your phone to your pet eagle or something?).
C] ODK-2
The community of developers has responded and now launched ODK-2. The original ODK is still operational as ODK-1, and ODK-2 brings in a lot more ways to achieve synchronisations and customizations and all. I haven’t gone though the whole thing yet, but it seems they’ve resolved the feedback I mentioned earlier.
Take a look at the tour here: https://docs.opendatakit.org/odk2/getting-started-2-user/#tour-of-the-simple-demo-application
So it seems to me like this platform is going to enable setting up survey exercises where the hierarchy is considerably flattened, and all the on-field folks can see what their colleagues are collecting and co-ordinate better. It seems like a good platform to run something like a citizens tree mapping or large area survey exercise on.
Screenshot:

Happy exploring 🙂
Disclaimer : I’m only rapid-sharing what I just stumbled upon, so will not be able to answer detailed queries right now. For that, check out ad join the forum. And see here the newsletter that sparked this post.
PS: Does your org use ODK? Then get yourselves listed on the users map, scroll to bottom of that newsletter to know how.
(this is a cross-post from an email. All opinions are personal. Author: Nikhil VJ, DataMeet Pune chapter)